| Python3的pytesseract和Tesseract | 您所在的位置:网站首页 › tesseract 训练接口 › Python3的pytesseract和Tesseract |
Python3的pytesseract和Tesseract
|
Python3的pytesseract和Tesseract-ocr的使用以及自己训练数据集的方法。 一、安装pytesseract pip install pytesseract -i https://mirrors.aliyun.com/pypi/simple/二、安装PIL和pillow库 三、下载Windows tesseract-ocr并配置其环境(网上有很多教程大家可以自行收集),内容和配置python的编译环境差不多。 四、修改pytesseract.py 到你的Python的Lib\site-packages\pytesseract中找到pytesseract.py并修改其中的tesseract_cmd 修改为:(亦可以报错后直接找到该文件后修改) tesseract_cmd = 'D:/Tesseract-OCR/tesseract.exe'(环境位置)五、训练数据集 (1)下载jTessBoxEditor(网上搜索,可自行下载) (2)安装jdk1.8以上的环境 (3)准备训练的标本,比如我的:you dont konw how hard to understand(有单词错误请自行忽略),图片越多越好,但是为了方便,此处随便打字并截取图片,大家可以自行选择。
(4)将照片转化合并为tif格式,方便数据训练。
选择merge TIFF,并选择图片,然后将它保存。 (5)在新建的tif文件夹的导航栏输入cmd,弹出命令行窗口。 (6)按照图片进行设置
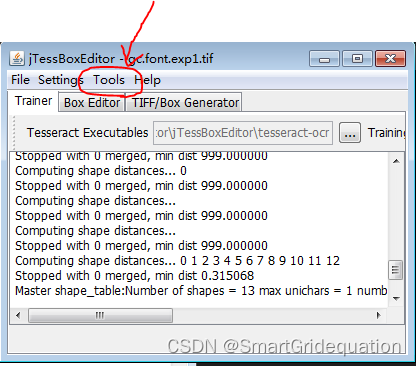
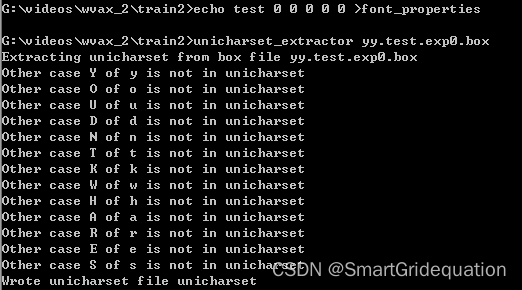
(7)训练语言设置为yy,训练文件夹自行选择好,之后选择make box file only,点击run。 (8)在cmd命令行处依次输入: tesseract yy.test.exp0.tif yy.test.exp0 nobatch box.train echo test 0 0 0 0 0 >yy.font_properties unicharset_extractor yy.test.exp0.box
(9)选择如下图,点击run:
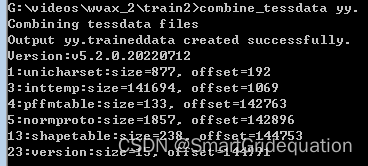
(10)最后执行: combine_tessdata yy.
(11)将生成的“yy.traineddata”语言包文件复制到Tesseract-OCR 安装目录下的tessdata文件夹中 Log输出中的Offset 1、3、4、5、13这些项不是-1,表示新的语言包生成成功,就可以使用训练生成的语言包进行图像文字识别了。 (12)代码测试 from PIL import Image import pytesseract img = Image.open("G:\\videos\\wvax_2\\train2\\yy.test.exp0.jpg") ocr_str = pytesseract.image_to_string(img,lang='yy',config = "--psm 7") print(ocr_str)效果:
至此完成了数据训练和使用,看代码应该简单明了的知道如何使用yy训练数据集了,该方法生成的tif还可以通过 jTessBoxEditor修改,最终提高识别效果。具体方法请自行搜索,关于该库的使用和环境配置就介绍到这里,谢谢你的阅读。如文章有不懂的地方,请私信或者留言。 |
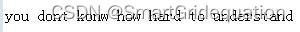



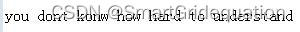

【本文地址】